前言
最近有个需求,要获取一些权威安全公众号的及时消息推送,于是就做了一下微信公众号的爬虫调研。最常见的肯定是抓微信请求的包,然后进行分析等等。这里通过搜索发现可以调搜狗微信搜索的查询接口,就用了这个方法,弊端是只显示最近十篇文章。另外还有一种方法是利用微信个人订阅号,在新建素材时,通过查找文章可以查到全部文章,这里没有这个需求,暂未采用。
接口

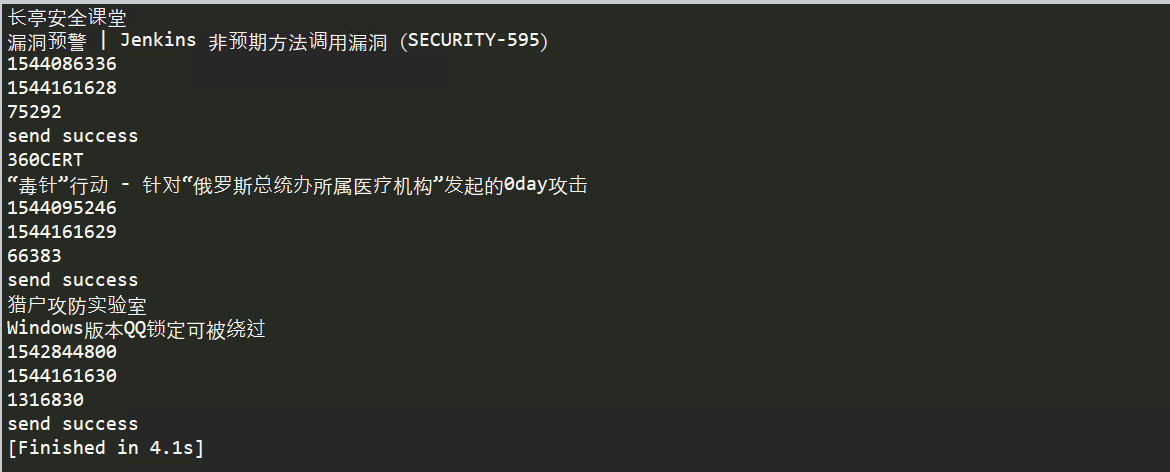
这里以长亭安全课堂为例,成功拿到了最近十篇文章的内容
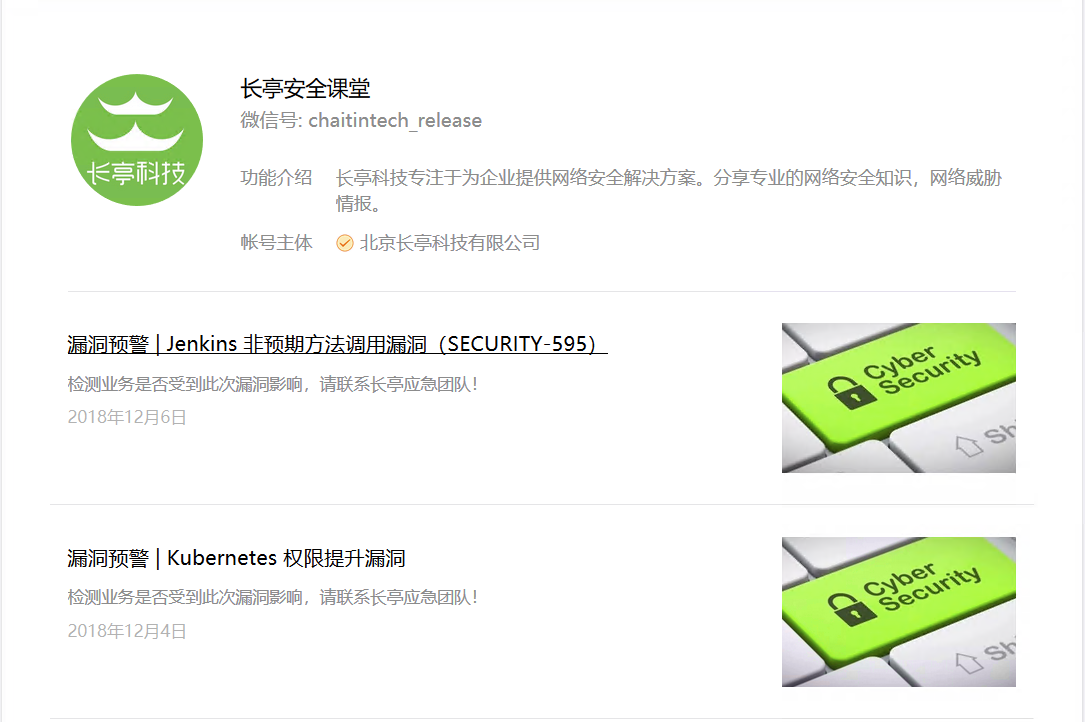
效果图

代码
1 | #-*- coding:utf-8 -*- |
说几点
搜狗这个网站也是有请求频率限制的,应该是针对ip,同一时间段请求次数过多,需要验证码的输入,这里暂未处理这个问题。邮件推送设置每30分钟爬虫运行一次
代码中利用js2xml库来处理返回包的script文本数据,然后利用xpath定位元素,如有更方便的方法,更好。
反爬
经过测试发现,腾讯设置反爬的策略,脚本不能长时间定时推送,切换ip可以重新请求,或者输入验证码进行验证。
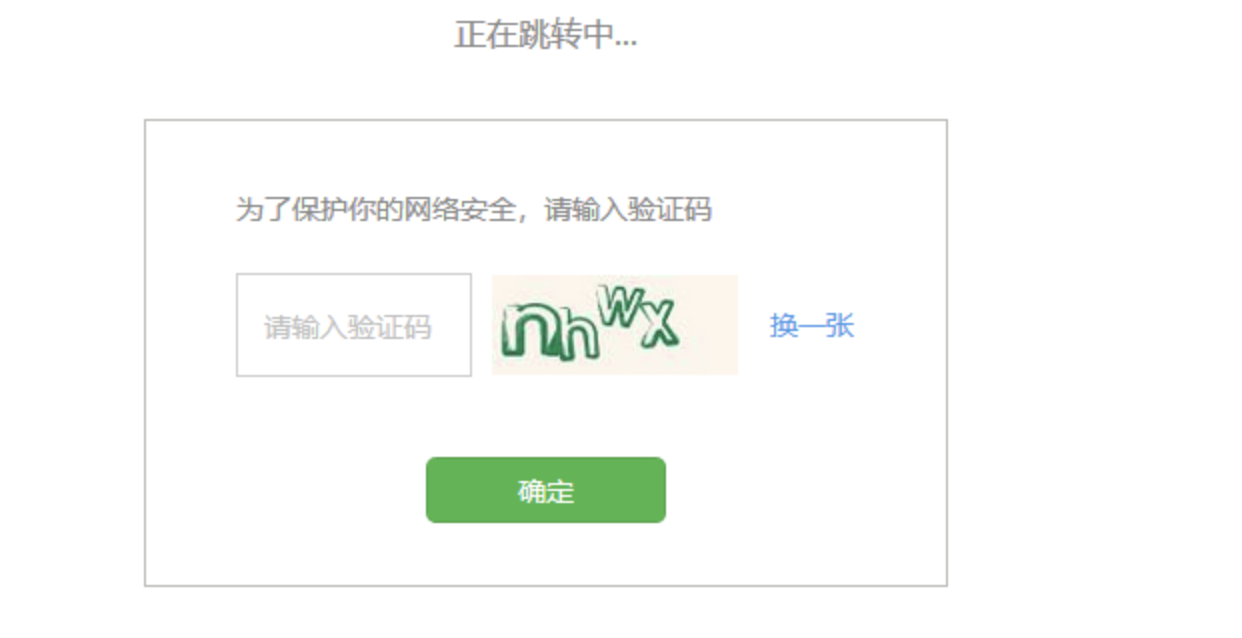
使用代理池的话,如果用网上免费代理池进行轮询也不算稳定,也就没有尝试。于是想尝试对验证码进行识别进行自动验证。通过对验证码的识别测试,发现识别率可以达到100%。这里首先用Python的pytesseract发现效果不好,当然可以通过训练字库的方式,然后再修改默认的字库加载文件,从而识别。另外就是用万能英数软件接口识别,非常准。
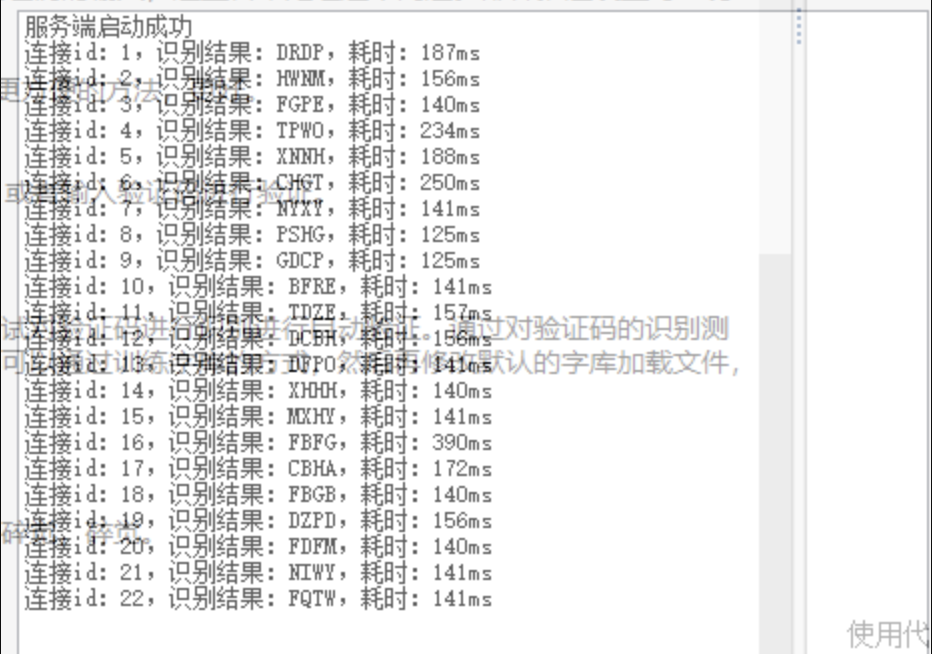
可是在提交请求POST包时,存在的参数cert值,对应验证码的时间戳却无法从链接或者返回包等等找到,于是就算识别方便,也暂时搁浅了。
最后又想到自己的需求,其实只需要抓最新一篇文章就行,于是发现在前一步的请求也可以做到,而且并未触发反爬验证码
1 | def get_info(url,table,a): |
只对此函数做了稍微修改,其他绕过反爬的还在测试。看到有之前的文章前面请求通过webdriver绕过,尝试不行,于是咱是用这种。
修改
上面的文字是之前写的,长时间去抓取搜狗微信的内容,肯定受到反爬策略的影响,就算只抓一篇文章也会最终被封IP,导致脚本不能正常运行。首先尝试的是代理池,找了一些免费代理池,先爬取代理池,然后Test测试能否使用,免费代理中有一部分可以使用,但是几乎没有IP可以抓取搜狗内容,返回如下:
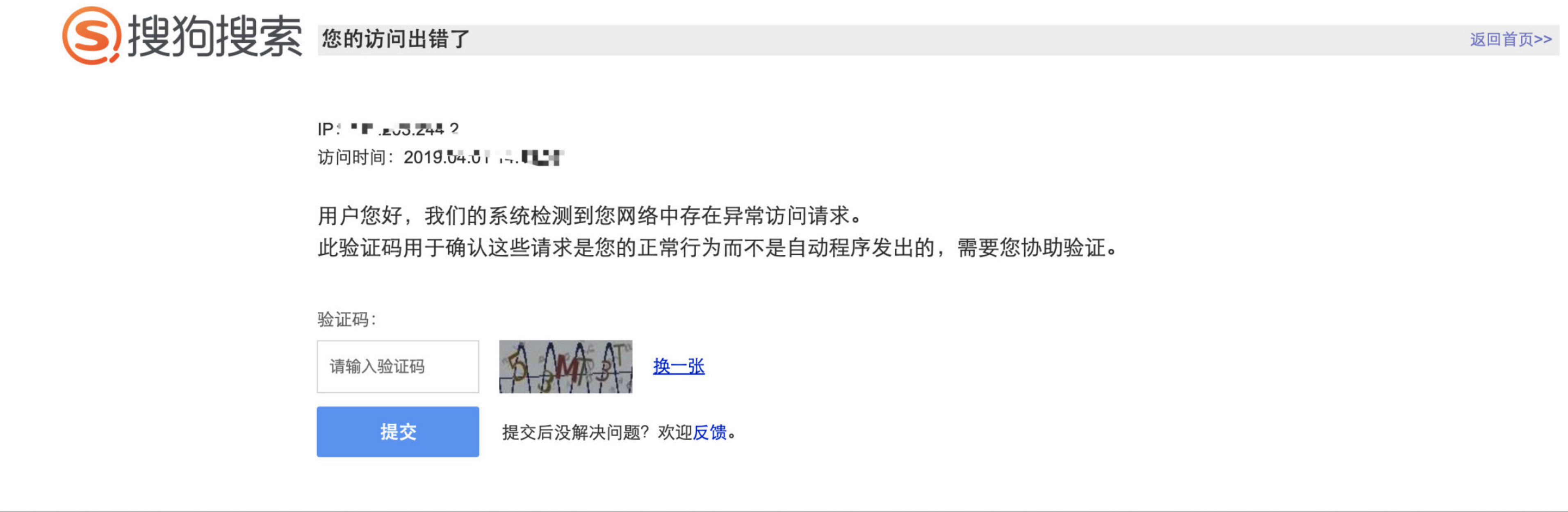
查看反爬的提交验证码解封的ajax请求,有如下js
1 | $(function() { |
在提交验证码后,会解封IP,生成新的SNUID,从而继续利用新Cookie请求。
代码如下:
1 | def cookie_init(): |
最后
又到周末了,是不是很开心呢,不知道你们怎么过,反正我已经被冻成狗了,我要碎觉,碎觉,碎觉。