0x01前言
前两天在地铁上看公众号,无意中看到有爬取豆瓣影评以及对爬取数据进行数据分析的文章,加上前段时间并未对机器学习进行实践,就打算从文本数据处理开始,后期再写一些CNN或者RNN模型等机器学习文章。然后就是最近《后来的我们》电影比较火,话说我还没去看呢,就以此为目标牛刀小试吧。先是爬取观众的影评,进行文本数据处理,再将文本数据提取特征转化为向量模型,利用机器学习来检查恶意评论,目前代码也只是Demo版本。
0x01代码结构
废话不多说,先看代码结构。
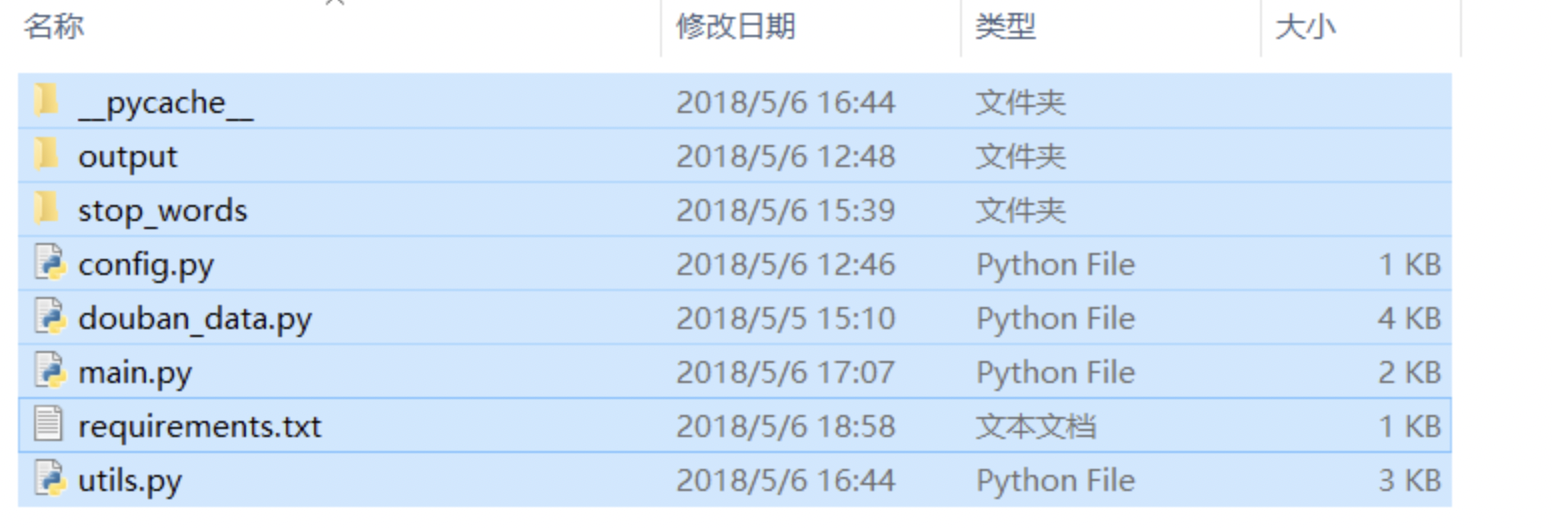
最后的效果图,提供了两种机器学习的模型,一种是SVM,这里SVM模型提供了三个相差较大的参数;另外一种是朴素贝叶斯。因为只是做了一个二分类,所以同样可以使用的分类模型还有很多,像KNN,逻辑回归等等,都可以使用。
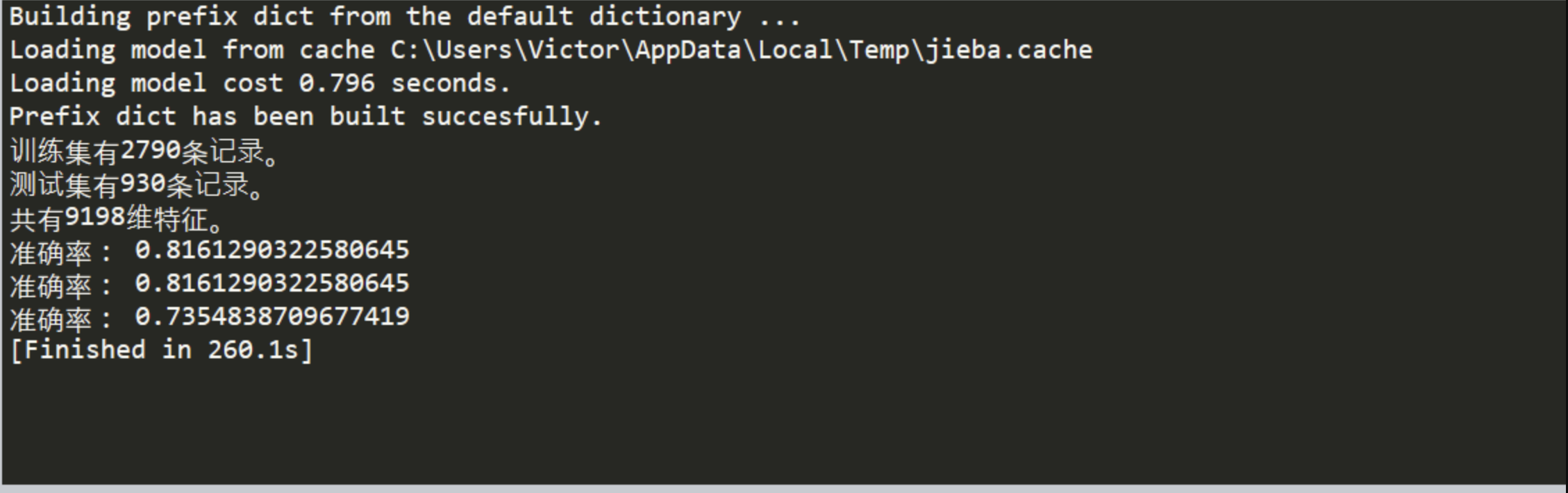
这是利用SVM模型进行学习获得的准确率
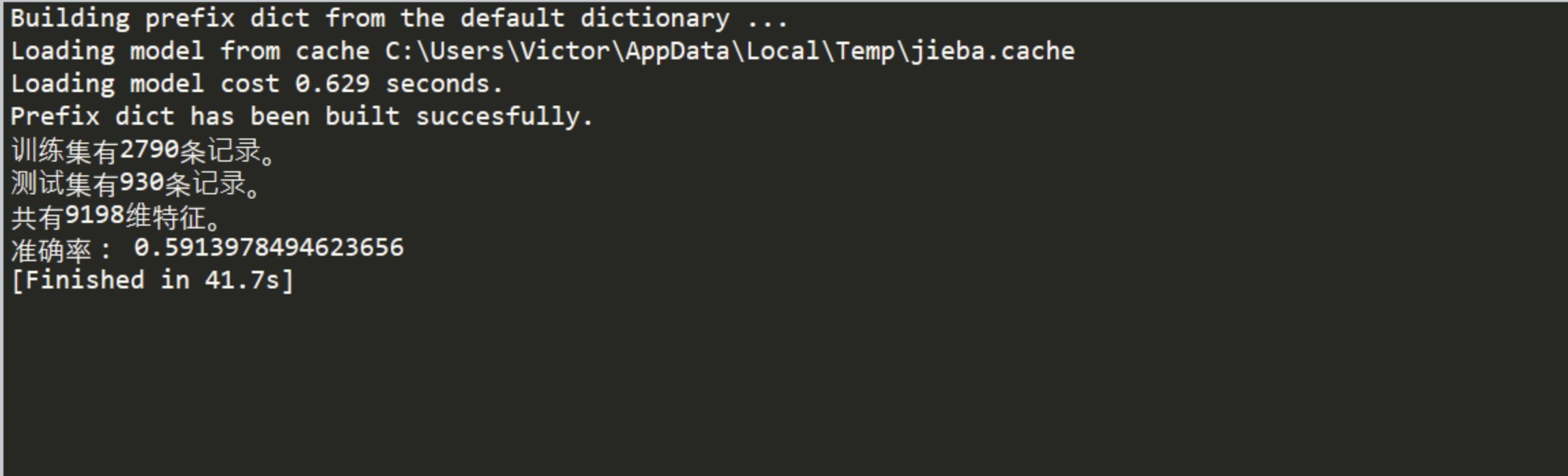
这是利用朴素贝叶斯进行学习返回的准确率
当然这里关于学习的准确率,与数据集也有很大关系,由于爬虫时获得的数据未展开,只是静态爬虫,加上对文本特征处理的方法不完善,都会对准确率有一定的影响。
0x02实现过程
第一步当然是爬虫了,我这里采取的是静态爬虫,我是昨天爬取的豆瓣《后来的我们》影评,大约有3700条左右数据。爬取完之后发现一些较长的评论需要交互式点击爬虫,方能展开。所以仅利用静态爬虫的数据进行分析了,后期可以再修改爬取的数据吧。
这里爬虫的部分,提取了两个内容。一是影评,二是分值,也就是观众的打分,分1-5分,分别为力荐、推荐、还行、较差、很差。爬的时候发现有些观众只评论并没有打分,考虑到后期还要数据清洗,就将未打分的评论归为还行一栏,然后做了一个二分类问题。3-5分也就是力荐、推荐、还行设置标签为1,1-2分也就是较差、很差设置标签为0。
1 | while i < 3700: |
然后爬虫得到的数据保存为csv如下:

然后就是要对数据进行处理
1 | def prepare_data(): |
这里有一点注意,在将爬取 汉字数据存取为csv时,要注意编码格式,这里用的是GB18030方可正常显示,有时会用gb2312等,用utf-8会显示汉字乱码。
对数据集进行处理,添加两列,一列是label,另一列是对文本数据的处理,这里利用apply函数来转化
1 | def preprocess_text(raw_text): |
这个函数就是刚才的文本处理函数,其中引用一个停用词词库,在代码stop_words文件夹中。
通过过文本数据的处理,接下来便可以进行特征提取,也就是文本数据转化为向量数据进行分析。
1 | def feature_engineering(train_data,test_data): |
利用了TF-IDF特征提取和词袋模型进行特征提取,最后将特征横向合并。
1 | def SVC_model(): |
最后也就是简单的构造机器学习模型了,分类问题可用的模型有很多,这里选取了SVM和朴素贝叶斯,也没考虑过拟合等等优化,关于对机器学习模型优化的集成学习后期再实践吧。
0x03总结
关于对爬虫数据的获取,还有很多要需要学习的地方。数据是进行一切分析的基础,有了数据才可进行数据统计分析和机器学习等等。文本数据分析中关于中文和英文的处理还是略有不同,写代码的过程遇到的坑也是需要不断的实践来弥补。最近更博频率有点高,需要克制一下,需要我做的事还有很多,比如说我突发奇想,想做一个电台类似的节目,类似于Dj,我说真的,软件我都搞好了,请看
你们会喜欢吗? 下个路口,不见不散。