前言
关于正则表达式,一直是检索的利器。最近在用bs提取html标签值的时候,会遇到标签难提取的特殊情况,于是就想到了正则表达式。正则表达式之前也简单整理过,但是发现没几天就忘了,果然是温故而知新,可以为师矣。
正则基础
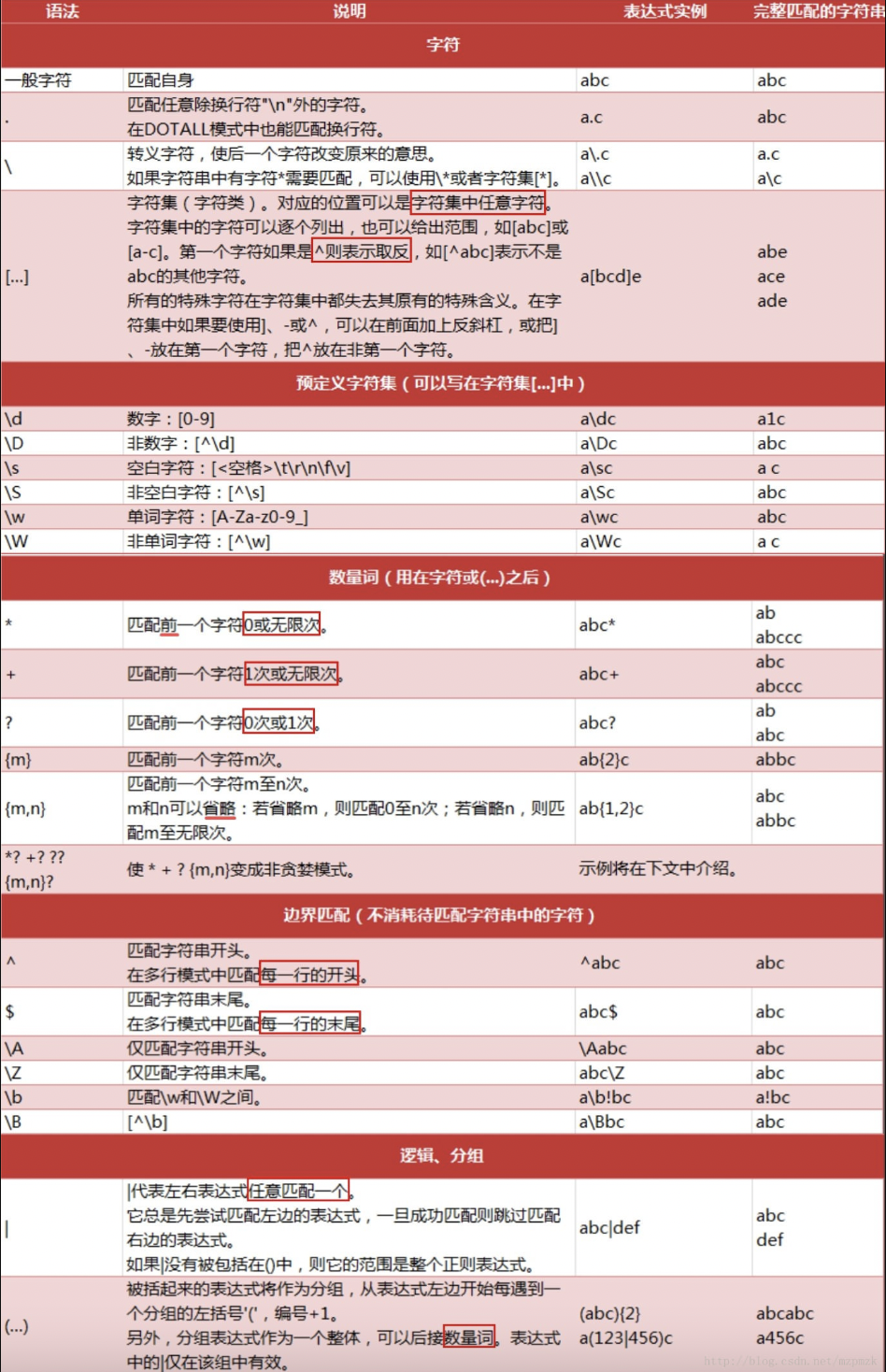
贪婪模式和
非贪婪模式
1
2
3
4
5
6
7
8
import re
ret_greed= re.findall(r'a(\d+)','a23b')
print(ret_greed) #贪婪
ret_no_greed= re.findall(r'a(\d+?)','a23b')
print(ret_no_greed) #非贪婪
['23'] #输出
['2'] #输出
正则表达式使用反斜杠” \ “来代表特殊形式或用作转义字符,这里跟Python的语法冲突,因此,Python用” \ “表示正则表达式中的” \ “,因为正则表达式中如果要匹配” \ “,需要用\来转义,变成” \ “,而Python语法中又需要对字符串中每一个\进行转义,所以就变成了” \ “。
为了使正则表达式具有更好的可读性,Python特别设计了原始字符串(raw string),raw string就是用’r’作为字符串的前缀,如 r”\n”:表示两个字符”\”和”n”,而不是换行符了。Python中写正则表达式时推荐使用这种形式。
开始使用
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果。
re.match()
Python提供了两种不同的原始操作:match和search。match是从字符串的起点开始做匹配,而search(perl默认)是从字符串做任意匹配
1
2
3
4
5
6
7
8
9
10
11
import re
pattern = re.compile(r'be')
a = 'To be or not to be'
match = pattern.match(a)
if match:
print(match.group())
else:
print('None')
None #输出结果
\\当pattern改为从To检索,则返回To
另外关于匹配的写法还可以这样:
1
2
3
pattern = re.compile(r'be')
a = 'To be or not to be'
match = re.match(pattern,a)
关于re.match对象有以下方法:
1
2
3
4
5
6
7
import re
a = "123abc456"
ret_match= re.match("a","abcde");
print(ret_match.group()) #返回返回被 RE 匹配的字符串
print(ret_match.start()) #返回匹配开始的位置
print(ret_match.end()) #返回匹配结束的位置
print(ret_match.span()) #返回一个元组包含匹配 (开始,结束) 的位置
常用的方法有group,默认输出的group其实是group(0),索引0会输出所有结果,如果进行分组检索,可以利用group的索引进行分组显示。
re.search()
将刚才例子的match改为search进行检索
1
2
3
4
5
6
7
8
9
10
import re
pattern = re.compile(r'be')
a = 'To be or not to be'
match = pattern.search(a)
if match:
print(match.group())
else:
print('None')
be #输出结果
只返回了一个be,可以看出search是从字符串做任意匹配,并且扫描整个字符串返回第一个匹配到的元素并结束,匹配不到返回None。
re.findall()
最常用的方法,以列表的形式返回匹配的字符串。
1
2
3
4
5
import re
a = 'one1two2three3four4'
match = re.findall(r'(\d+)',a)
print(match)
['1', '2', '3', '4'] #输出结果
re.split()
通过正则表达式将字符串进行分离。如果用括号将正则表达式括起来,那么匹配的字符串也会被列入到list中返回。maxsplit是分离的次数,maxsplit=1分离一次,默认为0,不限制次数。
1
2
3
4
5
6
import re
a = 'This5is2a1question'
match = re.split('\d',a)
print(match)
['This', 'is', 'a', 'question']#输出结果
re.compile()
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。第二个参数flag是匹配模式,取值可以使用按位或运算符’|’表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile(‘pattern’, re.I | re.M)与re.compile(‘(?im)pattern’)是等价的。
re.I(IGNORECASE): 忽略大小写(括号内是完整写法,下同)
re.M(MULTILINE): 多行模式,改变’^’和’$’的行为(参见上图)
re.S(DOTALL): 点任意匹配模式,改变’.’的行为
re.L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
re.U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
re.X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
这里re.S和re.M我们接下来检索html标签进行匹配会用到
re.S,它表示“.”的作用扩展到了整个字符串,包括”\n”,看一个例子:
1
2
3
4
5
6
7
8
9
10
11
12
import re
a = '''asdfhellopass:
123
worldaf
'''
b = re.findall(r'hello(.*?)world',a)
c = re.findall(r'hello(.*?)world',a,re.S)
print(b)
print(c)
[] #输出结果
['pass:\n\t123\n\t'] #输出结果
re.M 将字符串视为多行
HTML提取
获取标签间内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import re
language = '''<tr><th>性別:</th><td>男</td></tr><tr>'''
re_tr = re.compile(r'<tr>.*?</tr>')
tr = re.findall(re_tr,language)
for i in tr:
print(i)
re_th = re.compile(r'<th>(.*?)</th>')
th = re.findall(re_th,i)
print(th)
re_td = re.compile(r'<td>(.*?)</td>')
td = re.findall(re_td,i)
print(td)
<tr><th>性別:</th><td>男</td></tr> # 输出结果
['性別:']
['男']
[Finished in 0.1s]
当然很多时候可能不需要compiler,显得繁琐,另外这里对于html的dom结构来说,需要添加re.S|re.M参数进行检索,多行匹配。
获取超链接内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import re
content = '''
<td>
<a href="https://127.0.0.1/demo.php" title="This is a demo">How are you </a>
<a href="https://127.0.0.1/test.php" title="This is a test">Fine,thank you</a>
</td>
'''
#提取超链接之间的内容
pattern_1 = r'<a.*?>(.*?)</a>'
res_content = re.findall(pattern_1,content,re.S|re.M)
for i in res_content:
print(i)
#提取超链接的所有
pattern_2 = r'<a.*?>.*?</a>'
res_href = re.findall(pattern_2,content,re.S|re.M)
for m in res_href:
print(m)
#提取超链接的地址
pattern_3 = r'<a href="(.*?)".*?>.*?</a>'
res_site = re.findall(pattern_3,content,re.S|re.M)
for n in res_site:
print(n)
输出结果:
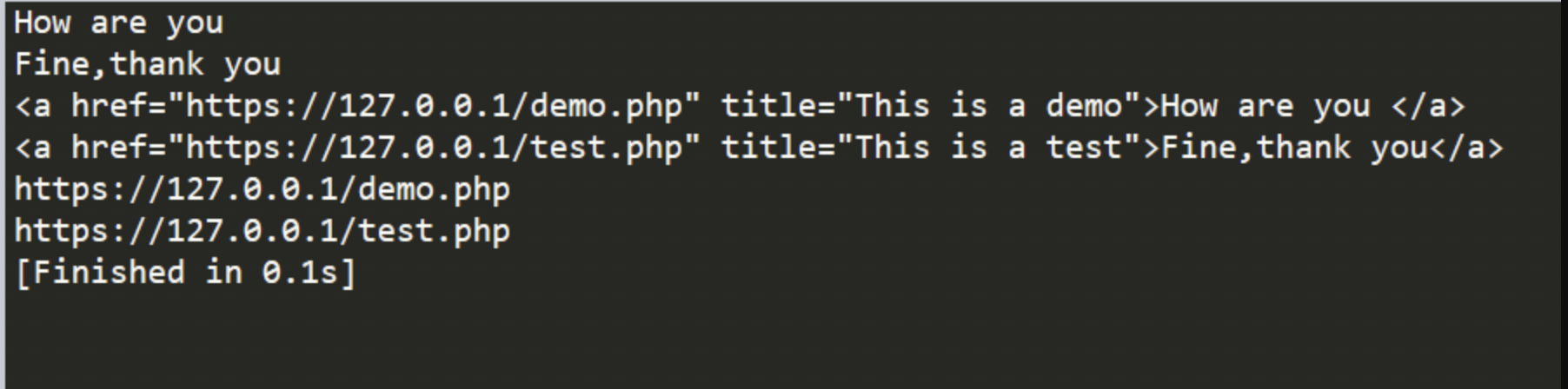
通过对正则表达式的利用,可以对HTML指定的位置进行检索提取,以上两个两个例子也足够说明如何提取标签内或者行间数据,只需要对标签进行修改即可。
结束语
正则表达式是处理字符串的强大工具,可以简化很多繁琐的工作步骤。今后还是要多多使用正则表达式,才可以熟能生巧的。本篇没什么难点,开始慢慢养成做笔录的好习惯。好记性不如烂笔头,似不似呢,下个路口见。